

QY Research Inc. (Global Market Report Research Publisher) announces the release of 2025 latest report “AI Inference Engines- Global Market Share and Ranking, Overall Sales and Demand Forecast 2026-2032”. Based on current situation and impact historical analysis (2020-2024) and forecast calculations (2026-2032), this report provides a comprehensive analysis of the global AI Inference Engines market, including market size, share, demand, industry development status, and forecasts for the next few years.
The global market for AI Inference Engines was estimated to be worth US$ 59327 million in 2025 and is projected to reach US$ 168243 million, growing at a CAGR of 16.3% from 2026 to 2032.
【Get a free sample PDF of this report (Including Full TOC, List of Tables & Figures, Chart)】
https://www.qyresearch.com/reports/6701060/ai-inference-engines
AI Inference Engines Market Summary
Definition and Scope
AI inference engines refer to software systems or hardware-software co-designed platforms specifically built to execute trained artificial intelligence models, analyze new incoming data in real time, and output prediction results. The fundamental distinction between AI inference engines and AI training systems lies in their functional orientation. Training systems focus on learning patterns and relationships from massive datasets, a process characterized by high computational intensity but relative insensitivity to latency. Inference engines focus on applying already-trained models to real-world scenarios, prioritizing minimal cost and maximum speed under constrained computational resources and stringent latency requirements.
From a product form perspective, AI inference engines can be categorized based on deployment location and computing mode. Cloud-based inference engines are deployed in data centers, utilizing powerful server clusters to process large-scale, high-concurrency inference requests. Edge inference engines are deployed close to data sources, such as factory production lines, retail locations, or traffic intersections. On-device inference engines run directly on mobile phones, smart home devices, and vehicles, imposing stringent requirements on chip power consumption and computational efficiency.
From a technical architecture perspective, AI inference engines have formed a clearly layered structure spanning hardware accelerators, software optimization frameworks, and application-layer vertical solutions. The hardware layer includes specialized chips such as GPUs, ASICs, and FPGAs. The software layer encompasses core components including model converters, inference runtimes, and hardware abstraction interfaces. The application layer provides packaged solutions for vertical scenarios such as autonomous driving, intelligent healthcare, and industrial quality inspection.
Figure00001. Global AI Inference Engines Market Size (US$ Million), 2021-2032
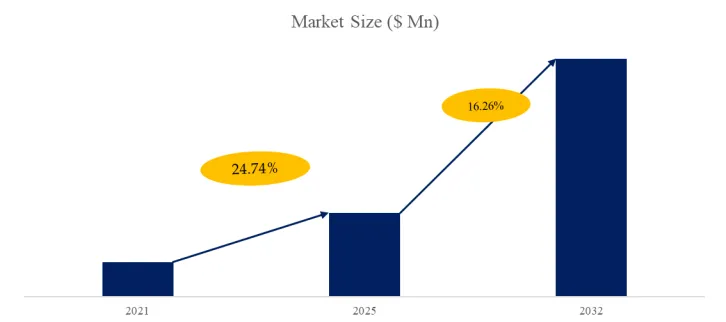
Above data is based on report from QYResearch: Global AI Inference Engines Market Report 2022-2031 (published in 2025). If you need the latest data, plaese contact QYResearch.
Industry Chain Analysis
Upstream segment: AI chip and hardware accelerator suppliers.
The upstream segment primarily includes chip design and manufacturing enterprises supplying AI computing power. Core products in this segment include GPUs for general-purpose AI computing, ASICs optimized for specific model architectures, programmable FPGAs, and various neural processing units. The technology roadmap choices of upstream chip suppliers directly determine the performance ceiling and power consumption profile of inference engines. Currently, GPUs maintain a dominant position in the data center inference market due to their versatility and mature software ecosystems, while ASICs are rapidly gaining market share owing to their energy efficiency advantages on specific workloads. The competitive landscape features a dominant leader with significant advantages, while AMD, Intel, and self-developed ASIC chips from cloud computing giants are becoming important incremental supply sources.
Midstream segment: inference engine software platforms and optimization tool providers.
The midstream segment is the core value node of the industry chain, transforming upstream hardware compute power into software tools and services usable by developers and enterprises. This segment includes two main categories of participants. The first category provides low-level operator libraries and runtime systems for AI framework developers. The core value of these products lies in maximizing the computational potential of specific hardware through techniques such as operator fusion, memory reuse, and low-precision quantization. The second category provides end-to-end inference deployment services for enterprise users. The technical barriers in the midstream segment are reflected in the breadth of adaptation to diverse hardware architectures, coverage of model compatibility across mainstream AI frameworks, and iteration speed in keeping pace with emerging model architectures.
Downstream segment: industry application developers and end users.
The downstream segment includes various industry application software developers, system integrators, and enterprise and government end users of AI inference capabilities. Downstream demand exhibits highly scenario-specific and vertical characteristics. Internet and e-commerce developers focus on inference performance for recommendation systems and search engines. The automotive industry demands high real-time performance and safety for autonomous driving perception models. Healthcare users are more sensitive to model explainability and regulatory compliance. Industrial manufacturing scenarios require deployment of inference engines in harsh factory environments. Downstream user selection decisions are not purely technical metric comparisons but comprehensive trade-offs involving performance, cost, deployment convenience, and ecosystem compatibility.
Figure00002. Global AI Inference Engines Top 19 Players Ranking and Market Share (Ranking is based on the revenue of 2025, continually updated)
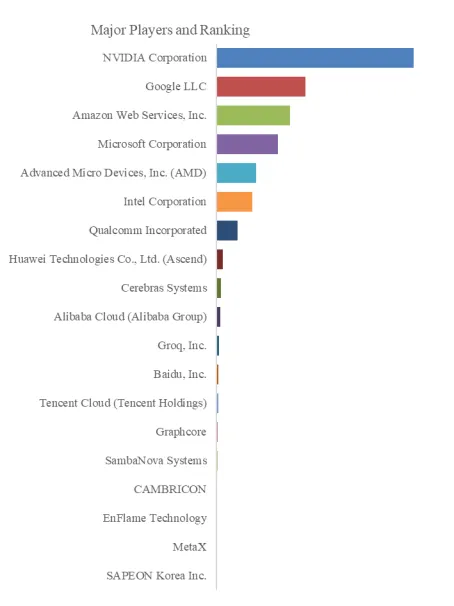
Above data is based on report from QYResearch: Global AI Inference Engines Market Report 2025-2031 (published in 2025). If you need the latest data, plaese contact QYResearch.
3. Overall Industry Development
The global AI inference engine market is in a structural growth phase transitioning from training-driven to inference-driven demand. With large language models and generative AI applications entering large-scale commercial deployment, inference is becoming the primary engine of AI compute demand growth and a new center of value distribution in the industry chain.
From a growth perspective, the AI inference market is experiencing rapid expansion. Industry data indicates the global AI inference market exceeded one hundred billion US dollars in 2025 and is expected to continue expanding at a double-digit compound annual growth rate toward 2032. Inference is increasingly positioned as a profit center within the AI industry chain. Every API call, agent response, and automated decision directly generates service revenue, motivating enterprises and developers to invest more resources in inference performance optimization.
From a technology evolution perspective, the AI inference engine industry is undergoing three profound changes. First, hardware architecture is transitioning from general-purpose to diversified forms. Second, deployment locations are shifting from centralized to distributed, with edge inference growth consistently outpacing cloud. Third, software tools are evolving from isolated offerings to integrated platforms that combine model development, data annotation, and application orchestration.
From a competitive landscape perspective, the AI inference engine market is forming a multi-layered, multi-path ecosystem. NVIDIA leads in core chips, while AMD actively pursues through acquisitions and software ecosystem development. Google TPU has become the workhorse within its own infrastructure and is being opened to external customers. Various AI chip startups target differentiated opportunities in specific scenarios. On the software platform side, managed inference services from cloud providers and open-source inference frameworks exhibit both competition and cooperation.
Key Development Characteristics
Characteristic One: Inference workloads shifting from batch processing to real-time interaction, driving dual demands for low latency and high throughput.
The mainstream adoption of generative AI applications has moved inference from backend processing to front-facing interaction. Users expect near-real-time interactive experiences. This requires inference engines to maintain single-request processing latency within acceptable bounds while sustaining high throughput. Real-time interaction scenarios require engines to respond quickly at low request volumes while scaling smoothly under high load. Innovative inference engines are exploring dynamic batching, predictive scaling, and adaptive scheduling mechanisms to achieve better balance between latency and throughput.
Characteristic Two: Technical trends including long-context inference and chain-of-thought reasoning impose new challenges on memory bandwidth and compute architecture.
Increasing context window lengths in large language models require inference engines to load and process longer input sequences in a single pass, creating growing pressure on memory bandwidth. The storage and access efficiency of KV Caches, critical intermediate states during Transformer inference, directly impacts inference throughput. Engine developers are implementing optimizations including better memory management strategies, more refined attention computation patterns, and reduced computational load through sparsity utilization.
Characteristic Three: Edge inference growth consistently outpacing cloud, driving inference engines toward lightweight and low-power designs.
The proliferation of IoT devices, intelligent terminals, edge servers, and autonomous vehicles is driving edge inference to grow faster than cloud deployment. Edge environments are characterized by limited computational resources, constrained power budgets and heat dissipation, unstable network connections, and data requiring local processing for privacy. The industry is developing inference-dedicated compute architectures, compressing model size by orders of magnitude while maintaining acceptable accuracy through quantization, knowledge distillation, and neural architecture search.
Characteristic Four: Hardware-software co-design becoming the core path for inference performance improvement, driving deep binding within industry ecosystems.
As single-chip performance improvements from Moore’s Law slow, industry consensus has formed around extracting performance gains through hardware-software co-design. Inference engines are no longer independent software layers but performance optimization tool chains deeply coupled with underlying chip architectures. This tight coupling means inference engine performance competitiveness increasingly depends on deep understanding of specific hardware platforms and forward-looking anticipation of model architecture trends.
Characteristic Five: Supply chain security becoming a strategic consideration, driving localized deployment and multi-sourcing strategies.
The dual-use nature of AI inference capabilities has led governments in major economies to elevate supply chain security considerations. GPUs and advanced AI accelerators in restricted trade categories face export controls to certain regions. Cloud service providers and large enterprises are proactively developing in-house AI chips to reduce dependence on external suppliers. For inference engine software, this means supporting heterogeneous hardware from diverse suppliers and ensuring consistent performance and compatibility across different chips has become a necessary capability. While product development complexity increases substantially, it also creates new opportunities for software platforms that can effectively abstract hardware differences.
Favorable Factors for Development
First, large-scale commercial deployment of generative AI applications is driving explosive inference demand growth.
Generative AI has moved beyond technology validation into a new cycle of scaled commercial adoption. Global technology leaders and industry pioneers are integrating generative AI into core business processes. Each user interaction corresponds to one or more inference calls. The emergence of AI agents performing multi-step tasks, potentially involving interactions with multiple tools and multiple model calls, significantly increases the number of inferences behind each user request.
Second, ongoing innovation in AI model architectures continues opening new technical frontiers for inference engine optimization.
The pace of model architecture evolution is not slowing. The emergence of Mixture of Experts, linear attention mechanisms, and state space models continues pushing model capability boundaries while creating new optimization opportunities. Mixture of Experts substantially reduces per-inference computational load by selectively activating only relevant expert modules. Techniques including quantization, sparsification, pruning, and knowledge distillation are rapidly maturing from academic research toward engineering practice.
Third, continued capital expenditure by data centers and cloud service providers is increasingly directed toward AI inference infrastructure.
The primary investment focus is shifting from training cluster construction toward inference infrastructure expansion. Traditional general-purpose server replacement cycles are also generating incremental demand for inference infrastructure. Servers purchased during the previous cloud investment boom are now entering renewal cycles, with newly deployed general-purpose servers increasingly handling pre-processing and post-processing tasks for AI inference.
Fourth, the thriving open-source ecosystem has lowered development barriers for AI inference applications and reduced startup experimentation costs.
The ecosystem of open-source AI models, inference frameworks, and toolchains has become exceptionally rich over recent years. Open-weight versions of major large language models now approach closed-source commercial model performance. Supporting open-source inference frameworks provide out-of-the-box high-performance inference deployment capabilities. Community contributions of optimization techniques and best practices enable developers to stand on the shoulders of giants.
Unfavorable Factors for Development
First, supply of high-quality inference chips remains constrained, with delivery lead times and cost control still industry pain points.
High-end AI inference chips still face supply-demand imbalances. Supply constraints have extended delivery lead times. Chip prices remain at high levels. While large cloud service providers can partially reduce dependence on external suppliers through in-house chip development, high hardware costs remain a significant factor constraining widespread deployment for startups and small to medium enterprises.
Second, rapid model iteration creates operational complexity, with inference engine compatibility costs remaining high.
The AI model field is in a period of rapid development, with new architecture models emerging frequently. Inference engine developers must simultaneously accommodate compatibility requirements across multiple model generations, multiple frameworks, and multiple deployment scenarios with limited resources. When upstream foundation models release superior new versions, inference service providers must promptly migrate to maintain service competitiveness. Model migration involves performance evaluation, compatibility verification, and potentially code modifications.
Third, variable inference latency affects user experience, particularly prominent in long-context and complex reasoning tasks.
While inference engines continue to optimize, the inherent autoregressive nature of generative AI tasks causes processing latency to increase with output length. When processing longer inputs or performing complex reasoning, both time-to-first-token and per-token generation time may fluctuate, affecting perceived smoothness. Enterprises often reserve resources based on peak requirements to guarantee service quality, leading to relatively low overall resource utilization.
Fourth, lack of standardized benchmarks for inference performance and cost evaluation complicates user selection.
Performance metrics promoted by different vendors are often measured under favorable conditions. Comparability across vendors is limited. Users often find that reported throughput or latency figures deviate significantly when reproduced in production environments. This information asymmetry leads to conservative decision-making favoring主流 solutions already validated in large-scale production environments, placing new entrants at a disadvantage.
Entry Barriers
First, depth of optimization experience for specific hardware platforms is a critical moat for software layers.
AI inference engine performance heavily depends on optimization depth for target execution hardware. Fully utilizing hardware parallelism, efficiently managing memory access, and reducing inter-core communication overhead require developer teams to possess deep understanding of chip microarchitecture. This domain knowledge is accumulated through long-term performance tuning practice rather than fully covered by public coursework.
Second, broad compatibility across mainstream AI frameworks and model formats requires sustained investment, with significant ecosystem lock-in effects.
Inference engines must handle model files from diverse ecosystems. Frequent updates to mainstream model frameworks require timely support for newly introduced operators. The release of open-source models introduces novel weight formats and special operator implementations requiring ongoing adaptation. This ecosystem lock-in means that once an inference engine has established a complete ecosystem network with numerous models and frameworks, developers and enterprises are reluctant to switch without compelling reasons.
Third, inference performance and cost quantification lack standardized benchmarks, complicating user selection.
The lack of fair third-party evaluation leads to information asymmetry in the buying process. Decisions based on public materials may deviate from actual needs, while building comprehensive in-house evaluation environments requires significant resources. This environment favors established players.
Fourth, inference security and compliance requirements add development and verification overhead for enterprise applications.
When inference engines are deployed in regulated industries, compliance costs compound significantly and may require custom adaptations for specific verticals. While this creates opportunities for specialized vendors, it also raises barriers for general-purpose platforms lacking deep domain partnerships. Consequently, some enterprises prefer vertically integrated solutions providing out-of-box regulatory alignment.
Value Distribution and Future Trends
From a value distribution perspective, upstream specialized inference chip designers and midstream enterprises with tightly coupled software optimization stacks capture excess profits in the industry chain. Upstream chip design companies achieve high margins through technical barriers and economies of scale. Excellent midstream inference engine software vendors generate sustainable revenue by providing developers with efficient, low-friction toolchains. In contrast, downstream application development and integration services face intense competition and relatively constrained profit margins.
Looking ahead, several directions may characterize evolution of the AI inference engine industry chain. First, hardware-software integration will deepen further. Second, inference engine intelligence levels will continue improving. Third, inference energy consumption will become a competitive focus. Fourth, the inference engine market will gradually transition from technology-driven to business-driven, with understanding vertical industry requirements becoming equally important as raw performance.
The report provides a detailed analysis of the market size, growth potential, and key trends for each segment. Through detailed analysis, industry players can identify profit opportunities, develop strategies for specific customer segments, and allocate resources effectively.
The AI Inference Engines market is segmented as below:
By Company
NVIDIA Corporation
Intel Corporation
Advanced Micro Devices, Inc. (AMD)
Google LLC
Amazon Web Services, Inc.
Microsoft Corporation
Qualcomm Incorporated
Cerebras Systems
Groq, Inc.
Graphcore
SambaNova Systems
Alibaba Cloud (Alibaba Group)
Baidu, Inc.
Tencent Cloud (Tencent Holdings)
Huawei Technologies Co., Ltd. (Ascend)
CAMBRI CON
EnFlame Technology
MetaX
SAPEON Korea Inc.
Segment by Type
GPU (Graphics Processing Unit)
TPU / NPU (Tensor Processor Unit)
ASIC (Application-Specific Integrated Circuit)
FPGA (Field-Programmable Gate Array)
CPU (Central Processing Unit)
Segment by Application
ealthcare (Medical Imaging, Diagnostics)
Automotive (ADAS, Autonomous Driving)
Retail & E-commerce
Banking, Financial Services & Insurance (BFSI)
Manufacturing & Industrial Automation
Others
Each chapter of the report provides detailed information for readers to further understand the AI Inference Engines market:
Chapter 1: Introduces the report scope of the AI Inference Engines report, global total market size (valve, volume and price). This chapter also provides the market dynamics, latest developments of the market, the driving factors and restrictive factors of the market, the challenges and risks faced by manufacturers in the industry, and the analysis of relevant policies in the industry. (2021-2032)
Chapter 2: Detailed analysis of AI Inference Engines manufacturers competitive landscape, price, sales and revenue market share, latest development plan, merger, and acquisition information, etc. (2021-2026)
Chapter 3: Provides the analysis of various AI Inference Engines market segments by Type, covering the market size and development potential of each market segment, to help readers find the blue ocean market in different market segments. (2021-2032)
Chapter 4: Provides the analysis of various market segments by Application, covering the market size and development potential of each market segment, to help readers find the blue ocean market in different downstream markets.(2021-2032)
Chapter 5: Sales, revenue of AI Inference Engines in regional level. It provides a quantitative analysis of the market size and development potential of each region and introduces the market development, future development prospects, market space, and market size of each country in the world..(2021-2032)
Chapter 6: Sales, revenue of AI Inference Engines in country level. It provides sigmate data by Type, and by Application for each country/region.(2021-2032)
Chapter 7: Provides profiles of key players, introducing the basic situation of the main companies in the market in detail, including product sales, revenue, price, gross margin, product introduction, recent development, etc. (2021-2026)
Chapter 8: Analysis of industrial chain, including the upstream and downstream of the industry.
Chapter 9: Conclusion.
Benefits of purchasing QYResearch report:
Competitive Analysis: QYResearch provides in-depth AI Inference Engines competitive analysis, including information on key company profiles, new entrants, acquisitions, mergers, large market shear, opportunities, and challenges. These analyses provide clients with a comprehensive understanding of market conditions and competitive dynamics, enabling them to develop effective market strategies and maintain their competitive edge.
Industry Analysis: QYResearch provides AI Inference Engines comprehensive industry data and trend analysis, including raw material analysis, market application analysis, product type analysis, market demand analysis, market supply analysis, downstream market analysis, and supply chain analysis.
and trend analysis. These analyses help clients understand the direction of industry development and make informed business decisions.
Market Size: QYResearch provides AI Inference Engines market size analysis, including capacity, production, sales, production value, price, cost, and profit analysis. This data helps clients understand market size and development potential, and is an important reference for business development.
Other relevant reports of QYResearch:
Global AI Inference Engines Sales Market Report, Competitive Analysis and Regional Opportunities 2026-2032
Global AI Inference Engines Market Outlook, In‑Depth Analysis & Forecast to 2032
Global AI Inference Engines Market Research Report 2026
About Us:
QYResearch founded in California, USA in 2007, which is a leading global market research and consulting company. Our primary business include market research reports, custom reports, commissioned research, IPO consultancy, business plans, etc. With over 19 years of experience and a dedicated research team, we are well placed to provide useful information and data for your business, and we have established offices in 7 countries (include United States, Germany, Switzerland, Japan, Korea, China and India) and business partners in over 30 countries. We have provided industrial information services to more than 60,000 companies in over the world.
Contact Us:
If you have any queries regarding this report or if you would like further information, please contact us:
QY Research Inc.
Add: 17890 Castleton Street Suite 369 City of Industry CA 91748 United States
EN: https://www.qyresearch.com
Email: global@qyresearch.com
Tel: 001-626-842-1666(US)
JP: https://www.qyresearch.co.jp







